
记录在Hadoop2.2.0中剔除一个DataNode
最近在Haddop环境下跑论文里的对比试验,不过这两天在跑Job时偶然会出现Job Failed的问题,看日志就是其中一台机器Connect Timeout了,在WebUI上点击这台机器IP的各种UI界面也是开不了,HDFS还连不上-_-|,之前也遇到过这种问题,解决方法简单粗暴:
- 重启
Haddop集群:一般重启一下还正好了
- 停
Haddop集群,然后重启每台物理机,然后再开启Hadoop集群:这么做一般问题就可以解决-_-| - 还有一种就是直接去
Linux上删除dfs文件目录,重新初始化HDFS:这么做效果虽达到了,但是。。。向HDFS传数据还很久一段时间。。
今天第1、2种方法试了都不行,第三种方法也太麻烦了(集群有15台DataNode+1台NameNode,重新初始化每次都要去每个机器上删除文件夹再新建),由于时间受限,就想尝试去动态的直接把那个老是异常的节点去掉得了,赶紧查了下面一些资料:
- http://blog.chinaunix.net/xmlrpc.php?r=blog/article&uid=23916356&id=3258527
- http://www.itpub.net/thread-1866448-1-1.html
- http://www.programgo.com/article/9436398293/
按参考上得现在hdfs-site.xml中添加:1
2
3
4
5<property>
<!--要摘除的datanode-->
<name>dfs.hosts.exclude</name>
<value>/home/nbu/hadoop2.2.0/etc/hadoop/exclude</value>
</property>
然后自己再相应目录下新建exclude文件并添加我要去掉的节点IP
再执行执行1
hdfs dfsadmin -refreshNodes
然后再需要摘除节点上去执行1
hadoop-daemon.sh stop datanode
接下来就可以在WebUI中看到我要去掉节点的状态为Decmission in Progress
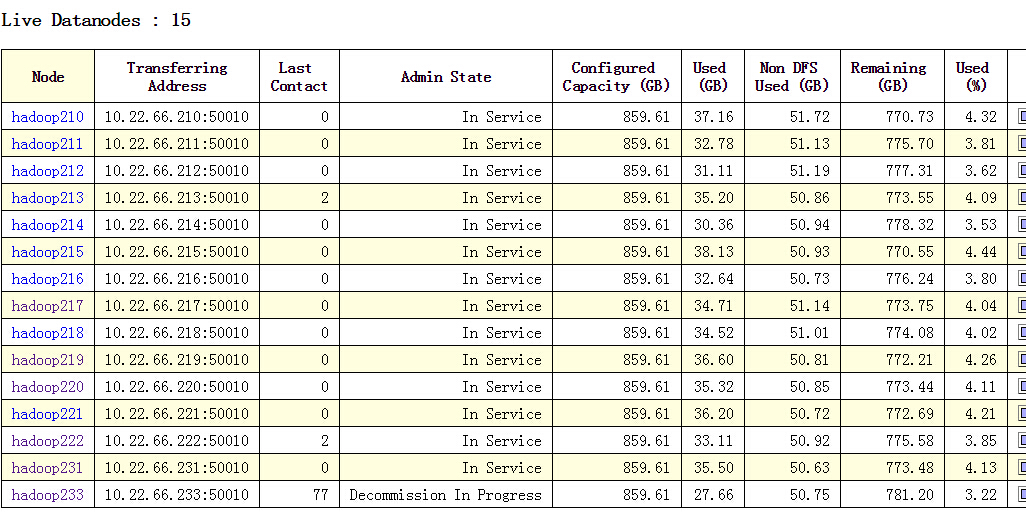
他们都说这个状态是正在将摘除节点的数据拷贝到其他可用节点,拷贝完之后不会变为我也就信了,可是我过了好几分钟我的状态一直是这个,当前可用集群的节点数量也是大于拷贝数量的,但是Last Contact的值一直在增加,不知道是不是那台机器上出问题了,然后与NameNode的心跳不正常导致的。十几分钟之后,这个节点没有出现在Live Nodes中了,但是他变为Dead Node里边去了,这回估计是直接超时了。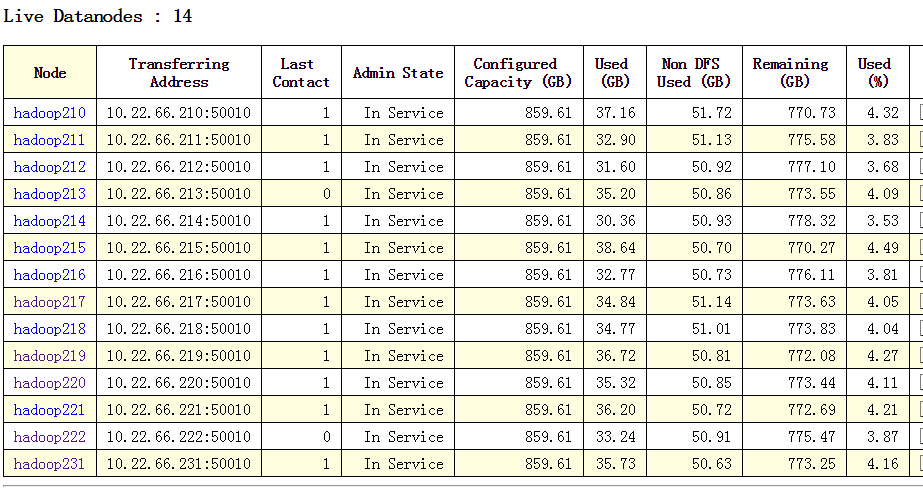
那怎么办?好像动态移除失败了?没辙,直接去NameNode机器上将slaves文件中将那个摘除的IP去掉,拷贝到各个DataNode上去。然后再重新启动Hadoop,这回重启了之后集群的hdfs上的数据皆正常^_^,那个需要移除的节点也不在集群中了,我又可以欢快得跑程序了。
不知道刚刚摘除的过程哪一步错了,不过最终还是达到我需要的摘除目的^_^,下次有时间再好好尝试尝试~
本作品采用[知识共享署名-非商业性使用-相同方式共享 2.5]中国大陆许可协议进行许可,我的博客欢迎复制共享,但在同时,希望保留我的署名权kubiCode,并且,不得用于商业用途。如您有任何疑问或者授权方面的协商,请给我留言。
