
使用IDEA搭建Spark源码环境及编译Spark源码
之前在看网上使用Eclipse搭建Spark的源码环境各种复杂,所以我只会spark source code下载下来,然后Import到Eclipse中,各种报错,各种包没有,还好我只是看看源码而已,不运行它报错也无所谓啦,人懒没办法..
但是现在想深入得学习一下Spark的源码环,就不得不搭建完整地环境,所以使用号称开发神器的IDEA来搭建Spark的源码环境,果然很方便^_^
准备工作
JDK1.7+Scala2.10.4(最好用这个版本,不然用最新版可能导致Spark出各种错误,点这里下载)IntelliJ IDEA 14 Community Edition(记得下载时选择社区版,它是免费的)Mac OS X 10.10.2(用其他环境也可以,但是别用windows啊)
从Github上clone源码
打开Idea,在欢迎界面别动!!!
点击Check out from version Control->Git
在弹出的界面上输入github上spark的托管地址http://www.jetbrains.com/idea/download/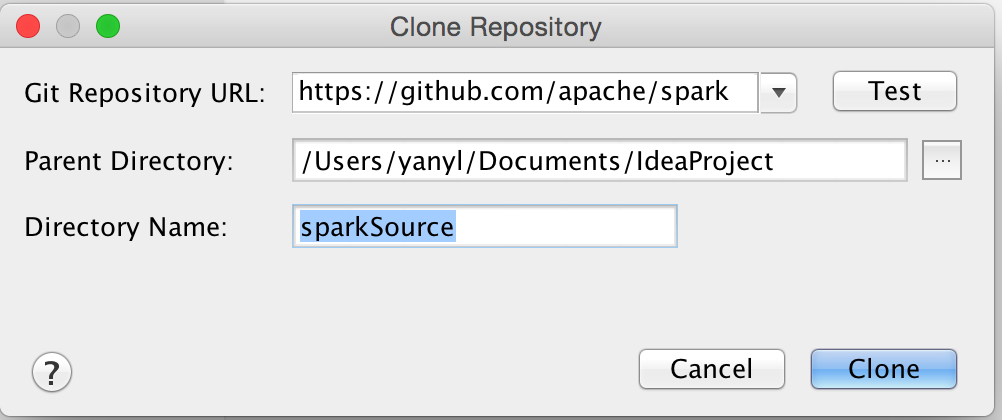
好了,你可以慢慢等了,我这里clone了半小时-_-网速不好啊。
pom.xml的依赖包下载
好不容易将Spark源码clone到本地了,这个时候idea会提醒你发现pom.xml,询问你是否下载其中的依赖,这个时候你要点“是”(Idea的强大之处就是会把这里的依赖全部给你下载了)。
好了,你又可以慢慢等待了,这个时候进度条在Idea右下角,想看进度的自己去点出来,我这里下载依赖貌似下载了一个多小时-_-
依赖包下载完成之后你就可以看Spark源码了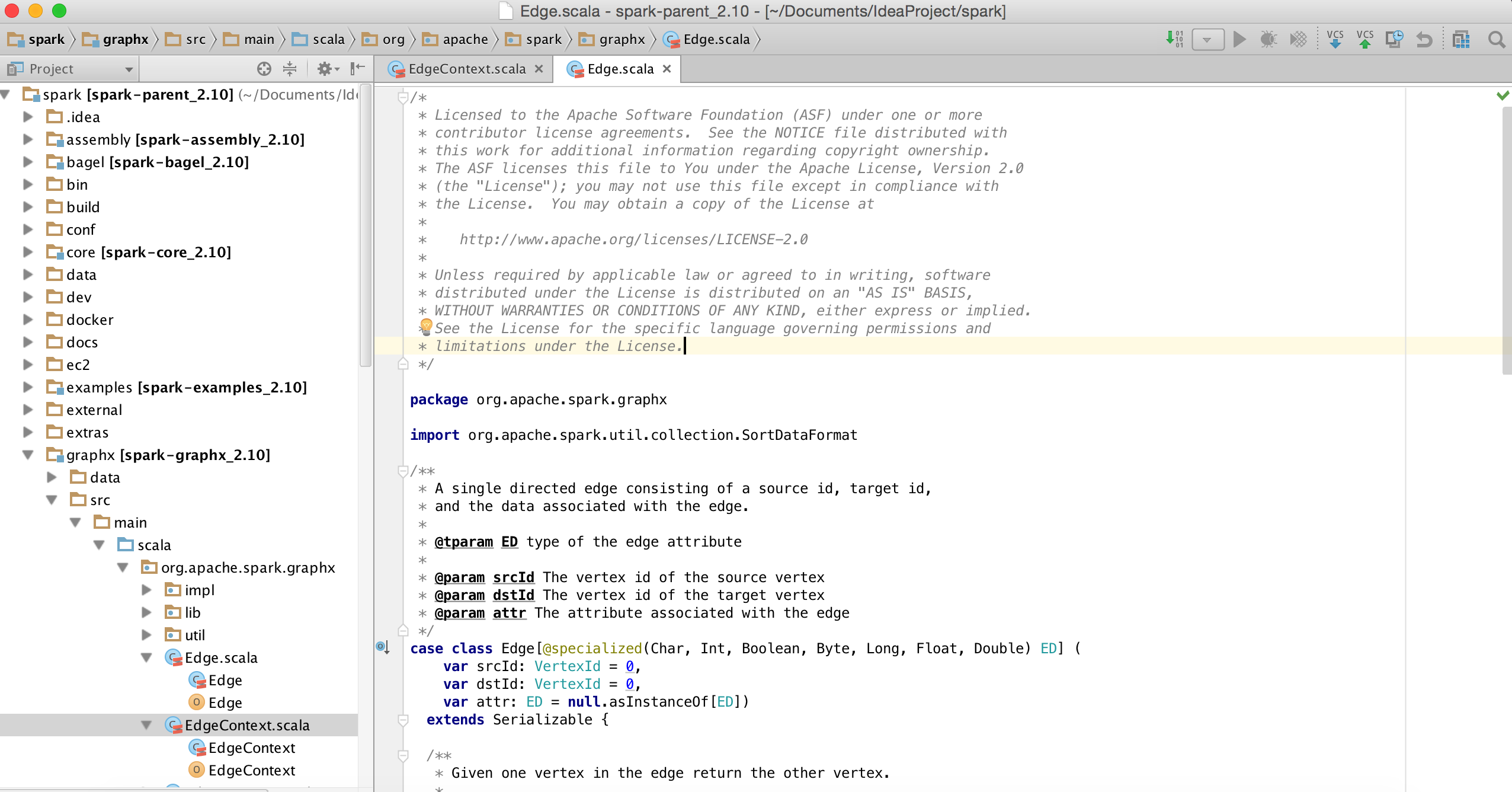
编译Spark源码
编译之前先打开pom.xml看java的版本确保和你本机的版本一样。1
<java.version>1.7</java.version>
然后打开终端iterm,进入sarpk的源码根目录,然后执行1
yans-MacBook-Pro:spark yanyl$build/mvn -DskipTests clean package
进行最终的编译,这里编译也是要花很多时间啊-_-,慢慢等吧,天朝的网络就是没办法。
如果想有其他的编译需求,比如Spark on Yarn:
具体看官网
http://spark.apache.org/docs/latest/building-spark.html#building-with-sbt,也还可以使用Sbt来进行编译,不过推荐使用Maven,因为他会下载Zinc来加速编译,还可以显示依赖的下载进度^_^。
编译完了之后控制台会输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] Spark Project Parent POM ........................... SUCCESS [ 5.915 s]
[INFO] Spark Launcher Project ............................. SUCCESS [ 11.219 s]
[INFO] Spark Project Networking ........................... SUCCESS [ 9.197 s]
[INFO] Spark Project Shuffle Streaming Service ............ SUCCESS [ 4.701 s]
[INFO] Spark Project Unsafe ............................... SUCCESS [ 4.131 s]
[INFO] Spark Project Core ................................. SUCCESS [03:29 min]
[INFO] Spark Project Bagel ................................ SUCCESS [ 7.715 s]
[INFO] Spark Project GraphX ............................... SUCCESS [ 21.757 s]
[INFO] Spark Project Streaming ............................ SUCCESS [ 40.511 s]
[INFO] Spark Project Catalyst ............................. SUCCESS [ 45.336 s]
[INFO] Spark Project SQL .................................. SUCCESS [ 52.931 s]
[INFO] Spark Project ML Library ........................... SUCCESS [01:10 min]
[INFO] Spark Project Tools ................................ SUCCESS [ 3.714 s]
[INFO] Spark Project Hive ................................. SUCCESS [01:02 min]
[INFO] Spark Project REPL ................................. SUCCESS [ 10.813 s]
[INFO] Spark Project YARN ................................. SUCCESS [01:41 min]
[INFO] Spark Project Assembly ............................. SUCCESS [01:25 min]
[INFO] Spark Project External Twitter ..................... SUCCESS [ 7.853 s]
[INFO] Spark Project External Flume Sink .................. SUCCESS [ 6.082 s]
[INFO] Spark Project External Flume ....................... SUCCESS [ 8.545 s]
[INFO] Spark Project External MQTT ........................ SUCCESS [ 6.492 s]
[INFO] Spark Project External ZeroMQ ...................... SUCCESS [ 6.426 s]
[INFO] Spark Project External Kafka ....................... SUCCESS [ 9.914 s]
[INFO] Spark Project Examples ............................. SUCCESS [01:34 min]
[INFO] Spark Project External Kafka Assembly .............. SUCCESS [ 31.930 s]
[INFO] Spark Project YARN Shuffle Service ................. SUCCESS [ 7.461 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 15:27 min
[INFO] Finished at: 2015-05-31T22:56:11+08:00
[INFO] Final Memory: 83M/653M
[INFO] ------------------------------------------------------------------------
现在你就可以在$SPARK_HOME/assembly/target/scala-2.10/下发现这个spark-assembly-1.4.0-SNAPSHOT-hadoop2.6.0.jar文件了,他可以在IDE中引用来开发Spark程序。
验证
为了验证编译结果,你可以到$SPARK_HOME/bin/目录下取执行spark-shell这个脚本:1
scala> val rdd=sc.parallelize(List(1,2,3,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:21
scala> rdd.count
//...此处省略log
res0: Long = 4
scala>
这里就可以运行local模式的Spark了,赶紧去体验吧~^_^
本作品采用[知识共享署名-非商业性使用-相同方式共享 2.5]中国大陆许可协议进行许可,我的博客欢迎复制共享,但在同时,希望保留我的署名权kubiCode,并且,不得用于商业用途。如您有任何疑问或者授权方面的协商,请给我留言。
