
长短期记忆模型-LSTM
RNN的缺点
RNN的特点毋庸置疑就是在训练/预测当前层节点时可以拿到先前层的数据来进行辅助计算,因此对于序列的学习非常有效。但事实上这个利用前面全部的信息并不是非常有效。比如看下面两个language mdoel:
the clouds are in the sky
这里要预测的sky只需要依赖前前面几个term即可
再看看另一个句子:
I grew up in France… I speak fluent French.
这里在预测French的时候需要前面较长的信息,甚至已经跨到前面一句话了。
因此是可以看出就算在Language Model中不同样本下可能是需要不同的长度的历史信息的,而对于RNN而言他并不能控制历史信息的长度.
LSTM的计算
而LSTM的设计之初就是为了解决RNN这种长期依赖的问题,一个最标准的RNN中每一个单元/层他是经过过一个tanh,结构是长这样的:
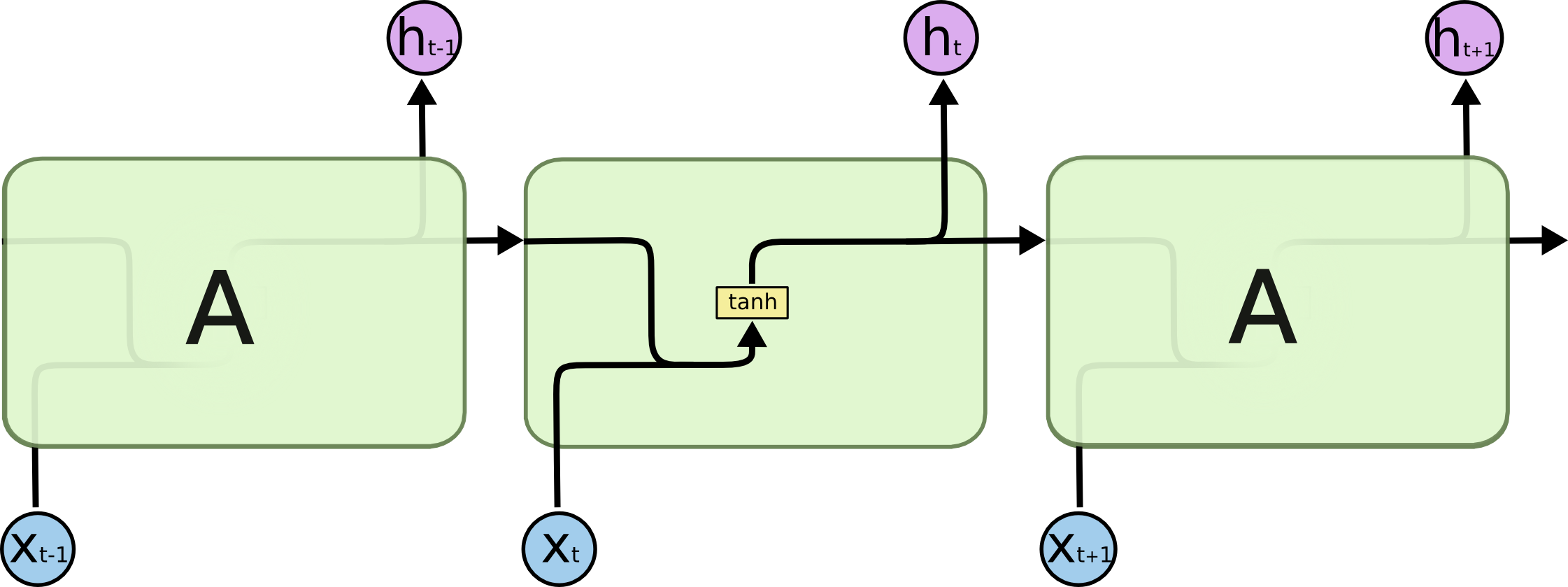
而LSTM的复杂很多,展开之后他是长这样的:
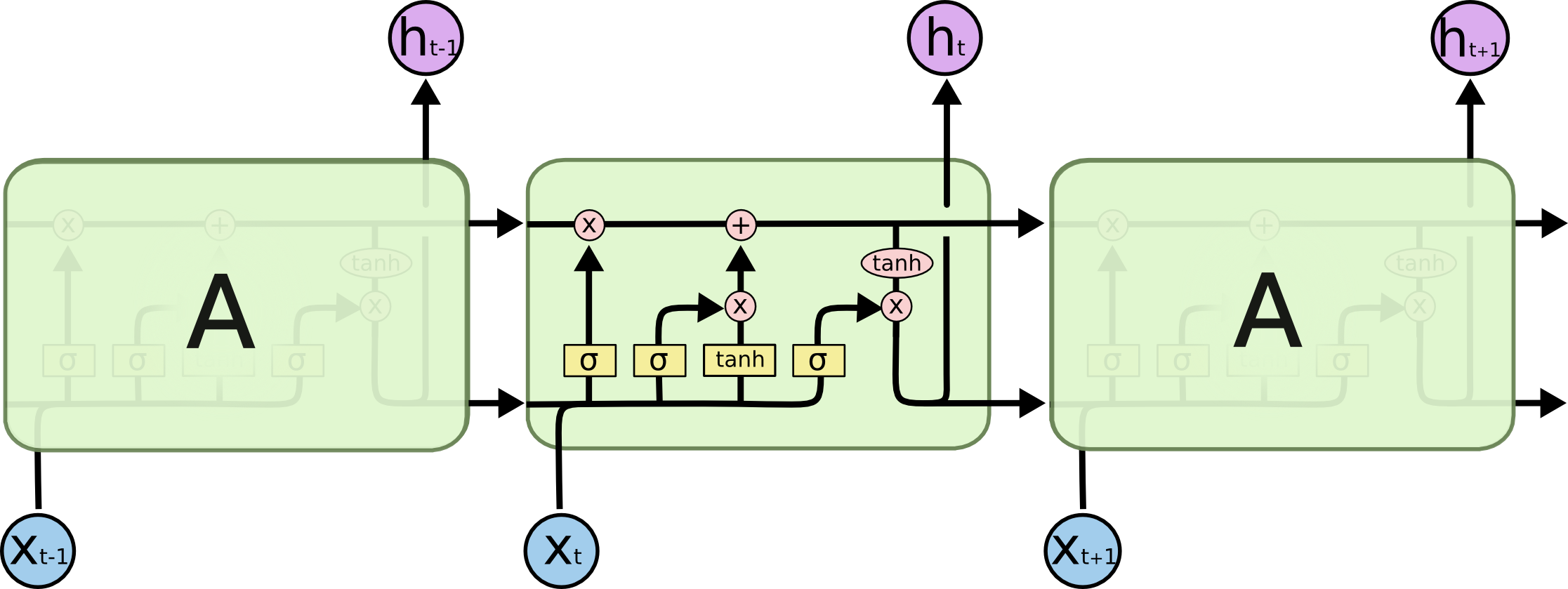
>
LSTM中最核心的就是门(gate)结构了,每一个gate经过一个sigmoid($\sigma$)结果输出一个0~1的输,可以精确的控制每一股的数据流量大小.接下来一步一步解析
LSTM单元内的每个小组件:第一步是决定哪些历史信息需要流入到当前的单元中,这里会经过
遗忘门(forget gate layer),作用对于历史信息的遗忘程度: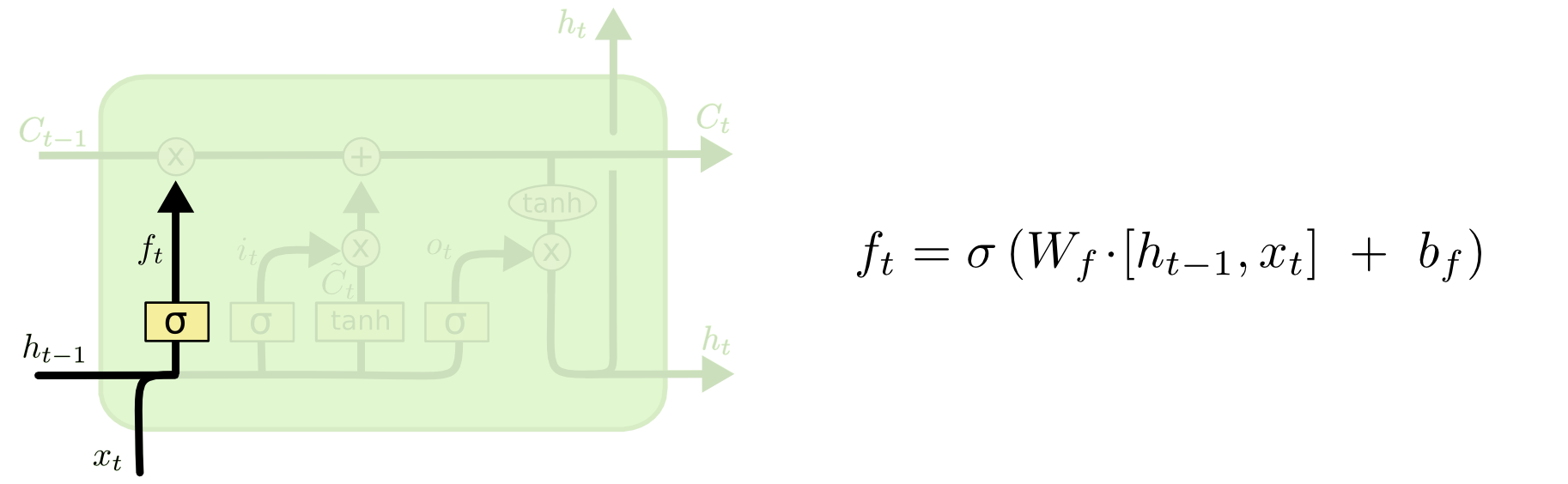
这个门的输入为上一层的隐含层信息($h_{t-1}$)和当前层的输入数据($x_t$),输出一个0~1的数字用于$C_{t-1}$,如果通过遗忘门之后输出1,则表示所有$C_{t-1}$的数据都保留,如果输出的0,则相当于$C_{t-1}$的数据经会被重置为0.
第二步是当前哪些信息数据需要流入到当前的组件中,首先会经过输入门(input gate layer)会决定哪些输入值需要更新,其次再经过一个$tanh$函数来生成一个新的$\tilde{C}_t$来与原先的$C_{t-1}$进行求和合并.
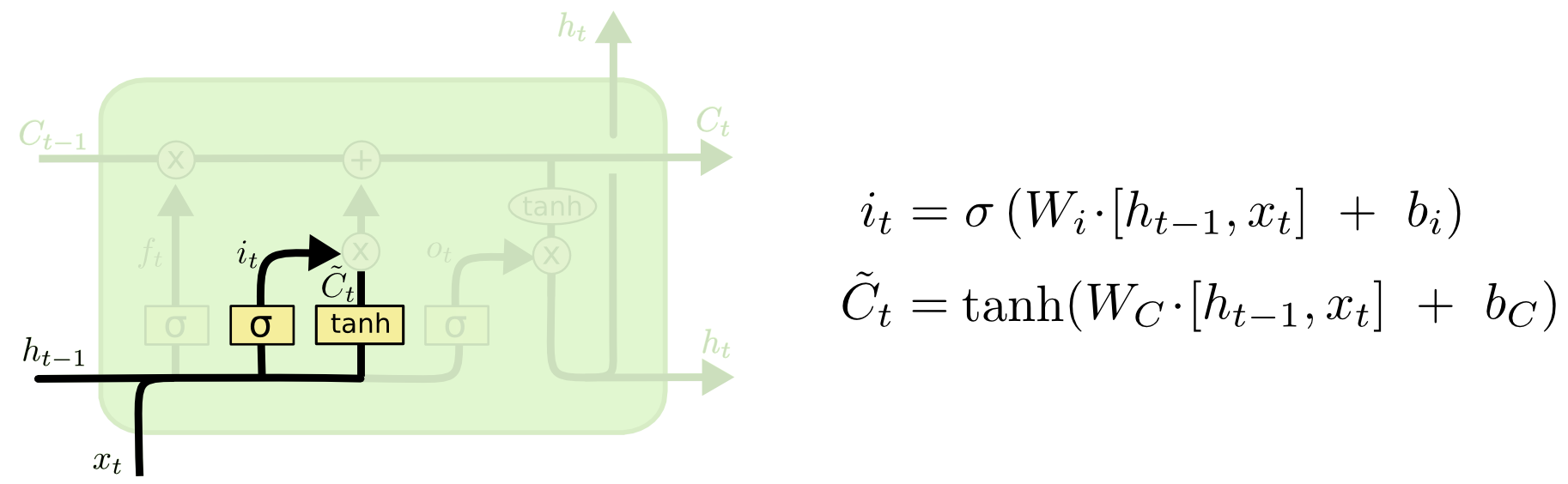
第三步是生成一个新的$C_t$值,它是综合$C_{t-1}$的遗忘信息以及当前新保留的$\tilde{C}_t$信息
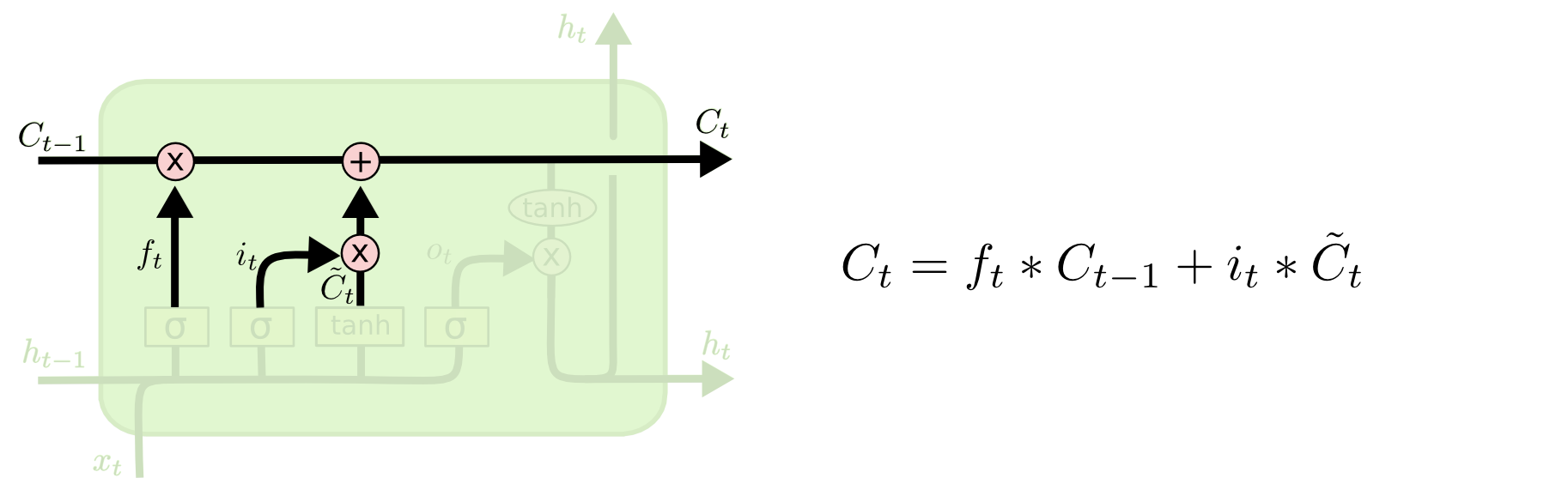
最后就是控制输出的数据了(就是输出隐含层单元的信息)
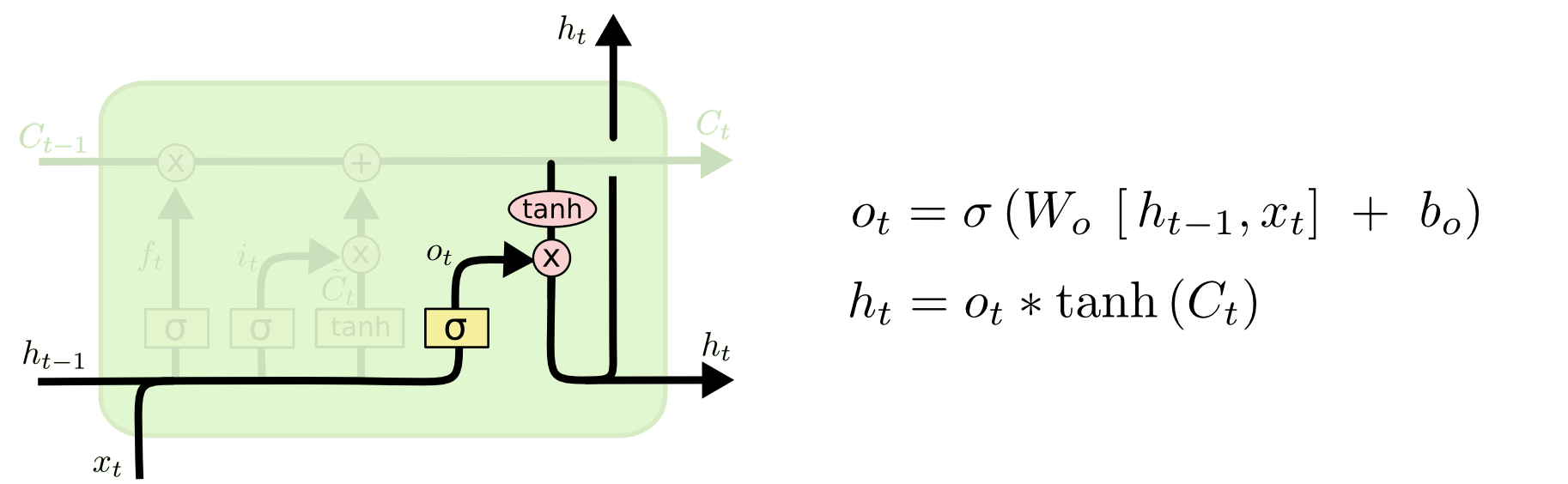
最终的输出是依赖当前的单元信息$C_t$,它经过一个$tanh$函数之后将数据scale到
-1~1,然后再通过一个输出门来控制需要数据的信息.上述4步是每个单元内的计算步骤,实际对于train目前应该还有一步$y_t=f(h_t)$,如果是
Language Model的话$f$就是softmax综合上面的图解,一个完整的
LSTM的单元里面的计算流程是这样:1. 遗忘门的计算:
$$f_t=\sigma(W_f \cdot [h_{t-1},x_t],b_f)$$
2. 输入门的计算:
$$f_i=\sigma(W_i \cdot [h_{t-1},x_t],b_i)$$
3. 当前单元信息的计算:
$$\tilde{C}_t=tanh(W_c \cdot[h_{t-1},x_t]+b_C)$$
4. 根据先前的单元信息$C_{t-1}$和当前的单元信息$\tilde{C}_t$,以遗忘门$f_t$和输入门$f_i$作为因子得到新的单元信息:
$$C_t = f_t \cdot C_{t-1} + f_i \cdot \tilde{C}_t$$
5. 输出门的计算:
$$f_o=\sigma(W_o \cdot [h_{t-1},x_t],b_o)$$
6. 根据新的单元信息$C_t$以及输出门$f_o$计算要输出的隐含单元信息:
$$h_t = o_t \cdot tanh(C_t)$$
7. 根据隐含单元信息计算训练/预测的目标:
$$y_t = f(h_t)$$
8. 一个单元计算完毕,回到
1进入下一个单元的计算## LSTM变种
上面描述的
LSTM结果其实还复杂的,比标准的RNN至少多了三个门单元($f_t,f_i,f_o$)以及单元信息$C$,多了这么多信息之后随之而言的就是计算量会增加许多,同时事实上很多任务中比不需要这么多信息,因此就会有较多的$LSTM$变种出现:下面这个变种是将
遗忘门去掉,其值改为$1-f_t$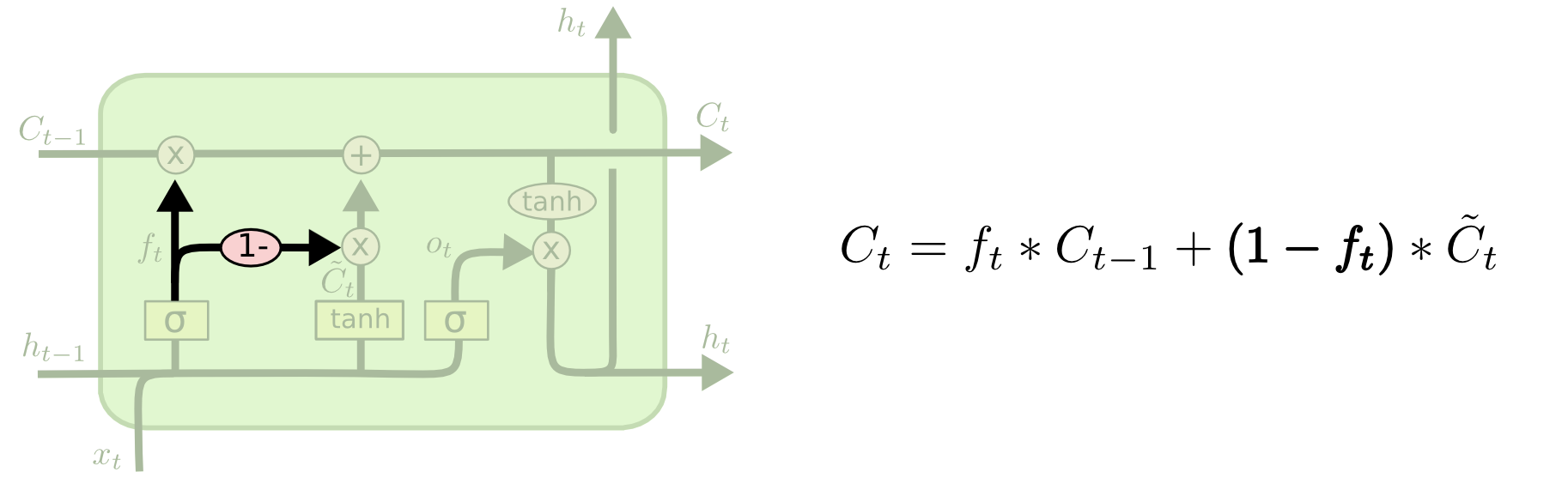
另外一个非常著名的变种就是GRU了

他将:
遗忘门和输入门合并为了更新门- 同时将
单元信息(cell state)和隐含信息(hidden state)进行了合并
从计算式子就可以看出整个单元的计算对比$LSTM$进行了极大的简化,但是其效果却几乎不降低。
当然还有很多其他的变种不再一一描述,可以参见参考
