来来来,学习Shell的命令
Shell脚本是非常强的大一个脚本语言,但是不用会手生,所以在此记录Shell脚本的相应关键点,也做查字典用^_^
变量
变量定义
先来简单的看一下变量定义的规则
- 在
Shell中,使用变量之前不需要事先声明,只是通过使用它们来创建它们; - 在默认情况下,所有变量都被看做是字符串,并以字符串来存储;
Shell变量是区分大小写的;- 在赋值变量的时候等号两端不能有空格-_-

Shell脚本是非常强的大一个脚本语言,但是不用会手生,所以在此记录Shell脚本的相应关键点,也做查字典用^_^
先来简单的看一下变量定义的规则
Shell中,使用变量之前不需要事先声明,只是通过使用它们来创建它们;Shell变量是区分大小写的;
给一个训练数据集和一个新的实例,在训练数据集中找出与这个新实例最近的k个训练实例,然后统计最近的k个训练实例中所属类别计数最多的那个类,就是新实例的类。
但是该算法每次在查询k个最近邻的时候都需要遍历全集 才能计算出来,可想而且如果训练样本很大的话,代价还是很大的,那有没有啥方法可以优化呢?本文就针对
KNN算法实现一个简单的KD树
KD树是一个二叉树,表示对K维空间的一个划分,可以进行快速检索(那KNN计算的时候不需要对全样本进行距离的计算了)
比如针对6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},可以形成以下树形结构以及空间划分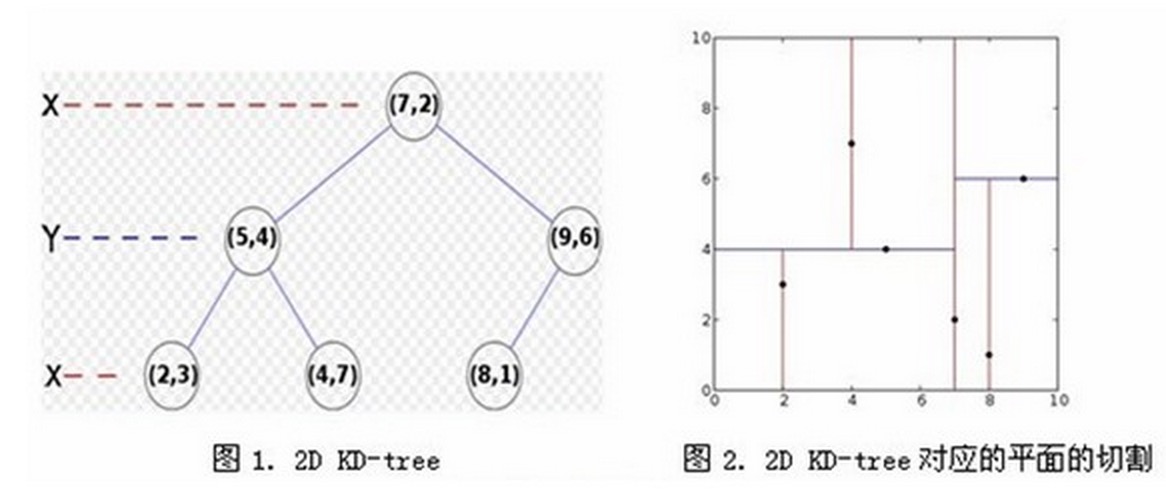
Scala语言是出了名的语法诡异,功能强大-_-,他的Iterator也是如此,还提供了亲民心的size/length方法,但是,但是,但是慎用!!
事情是这样的
今天在做这个:进行采样,在mapPartitions中操作,会传来一个Iterator迭代器,里面存着原始数据,我需要做的大概是先统计迭代器中的数量N(使用size方法来做),然后计算出一个需要采样的量n,然后遍历(直接for来做)这个迭代器,按自己的业务采样n个记录!
清晰明了的一个程序,这尼玛最终采样的变量一直是空,一直是空,一直是空。
起初还以为是概率那块算错了,导致采不出来,但是单独把程序剥离出来debuge发现这个for压根没数据,但是明明这个迭代器的里面的size是有值的啊,奇了怪了。。。
python相当方便,有问题可以直接查Doc,但是Doc略有繁琐,所以在词记下常用的一些技巧以及bug解决方案^_^
当然下面的判断完全可以自己使用正则表达式来些,但是有一句话是
杀鸡焉用牛刀,下面的api使用起来就会非常便捷
s为字符串
s.isalnum() 所有字符都是数字或者字母s.isalpha() 所有字符都是字母s.isdigit() 所有字符都是数字s.islower() 所有字符都是小写s.isupper() 所有字符都是大写s.istitle() 所有单词都是首字母大写,像标题s.isspace() 所有字符都是空白字符、\t、\n、\rpython中有两种排序方式:
list.sort(func=None, key=None, reverse=False):这种排序会改变list自身的数据sorted(list,func=None, key=None, reverse=False):这种会重新生成一个新的list最简单的栗子:1
2
3list=[1,3,4,2,4,7]
list.sort()
print list
会输出
[1, 2, 3, 4, 4, 7]
反向排序1
2
3list=[1,3,4,2,4,7]
list.sort(reverse=True)
print list
会输出
[7, 4, 4, 3, 2, 1]
对指定关键字进行排序:
list=[('a',100),('b',10),('c',50),('d',1000),('e',3)]
list.sort(key=lambda x:x[1])
print list
可以看到结果:
[('e', 3), ('b', 10), ('c', 50), ('a', 100), ('d', 1000)]
若不指定,貌似是按第一个关键词排序
还有两种方式均可以完成指定关键词方式:
1 | list.sort(lambda x,y:cmp(x[1],y[1])) |
1 | import operator |
按多关键字排序1
2
3list=[('a',100),('b',10),('c',100),('d',1000),('e',100)]
list.sort(key=lambda x:(x[1],x[0]))
print list
1 | import operator |
[('b', 10), ('a', 100), ('c', 100), ('e', 100), ('d', 1000)]
sorted传参一样,只是会返回一个新的实例而已
语法结构1
2
3
4
5
6try:
block
except [Exception as e]:
do...
finally:
do...
for Example:1
2
3
4
5
6
7try:
1/0
except Exception as e:
print 'err'
raise e
finally:
print 'end'
有时候需要载入的库是动态的,类似Java的反射
const_en.py1
name="xiaoming"
const_ch.py1
2
3#! -*- coding=utf-8 -*-
name="小明"
test.py1
2
3
4
5
6
7
8#! -*- coding=utf-8 -*-
import sys
const = __import__('const_en')
print const.name
const = __import__('const_ch')
print const.name
可以看到输出结果:
xiaoming
小明
在Python函数的入参列表中经常会看到*和**,他们其实并不是代表指针或者引擎,其中*表示传递任意个无名字参数,放置在一个元组中,比如1
2
3
4
5def array_para_test(a,b,*c):
print a,b
print c
array_para_test(1,2,3,4,5)
它的最终输出将会是
1 2
(3, 4, 5)
**表示任意个有名字的参数,用于存放在字典中进行访问,比如1
2
3
4
5def dict_para_test(a,b,**c):
print a,b
print c
dict_para_test(1,2,name="tome",age=23)
他的最终输出是
1 2
{'age': 23, 'name': 'tome'}
在机器学习的世界里面有非常多的模型(基石这个课暂时只讲了Perceptron Learning Algorithm,Linear Regression,Logistic Regression),各个模型也会有自己不同的特点,有各自长处,也有各自的短处,并且除模型之外,还有其他的附属选择,比如Regularization的类型,或者具体参数的值,比如Gradient Descent里面的步长等,我们知道,现在机器学习的目的就是得到最小化的Eout(也就是测试误差啦),那么现在给你一批数据,然后会出现上述那么多的选择,如果做才能得到最小的Eout呢?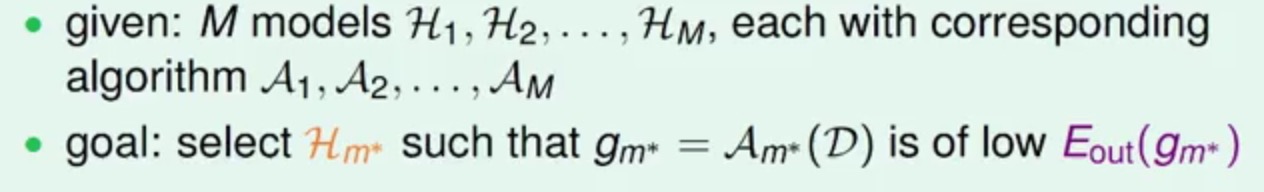
也就是我们要找到一个最好的模型Hm,使得Eout(gm)最小。
假设现在我们使用一个二次函数随机产生几个点,并且加入非常少量的噪声,然后使用一个四次函数来进行拟合
将得到如下的结果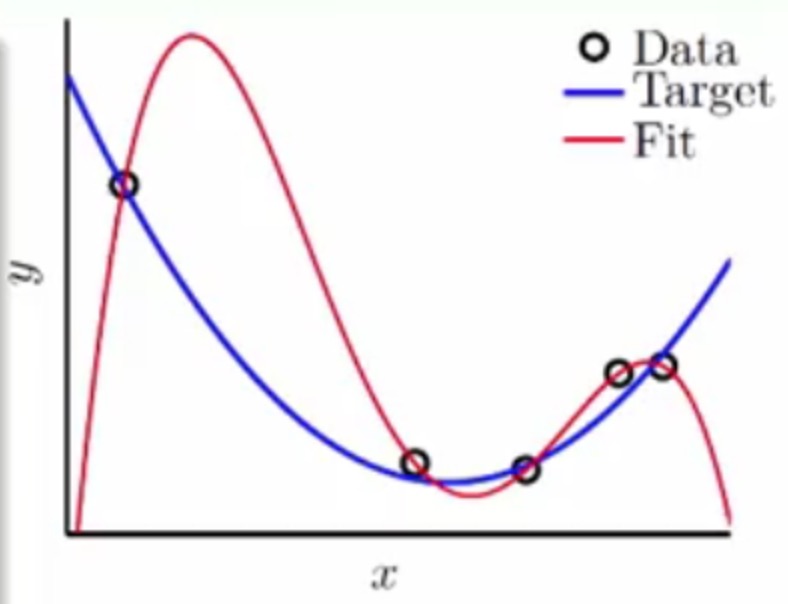
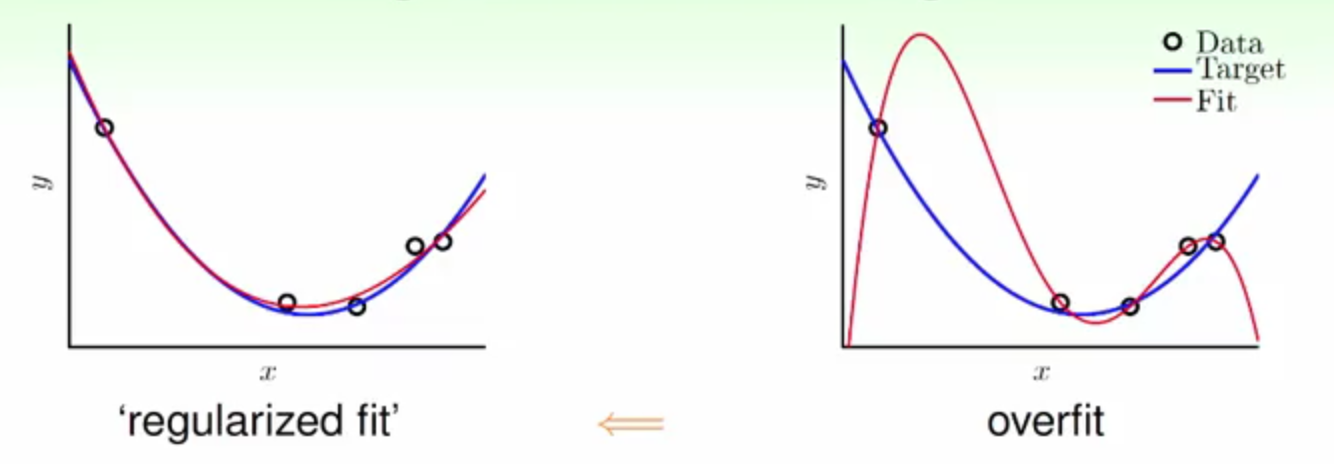
可以发现4次函数可以完全拟合含有噪声的2次函数产生的点,也就是拟合出来的Ein=0,但是此时如果使用新的2次函数的点用这个4次的拟合函数来进行预测的话,可以发现Eout会很高,
这种低Ein高Eout就是叫做泛化能力差(BAD generalization),也是往往我们在做训练预测时不希望看到的。
Perceptron Learning Algorithm,Logistic Regression这些算法的最初出现都是基于2分类的(Binary Classification),但是生活中会出很多多分类的问题出现(比如选择题:四选一,视觉的识别,手写体的识别之类的)
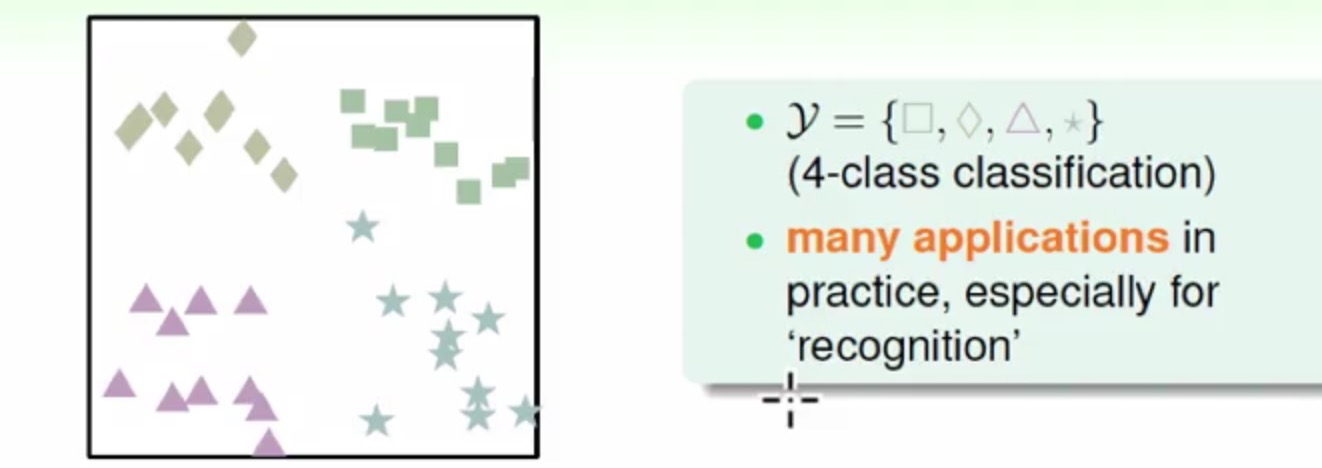

那么我们如何才能使用这些二分类的模型来完成多分类的需求呢?
前两篇文章中的模型Perceptron Learning Algorithm和Linear Regression可以解决的问题是判断一个患者是否会心脏病,但是实际生活中里面里面可能给出的报告的是患者患心脏病的一个概率: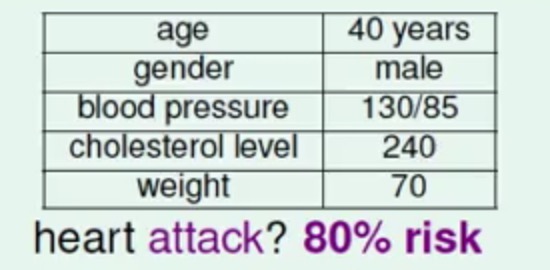
这样的话从模型的角度来说更希望的是得到一个发生在患心脏病的概率f(x)=P(+1|x)∈[0,1],
这个概率值越大,患心脏病的概率越大,反之则越小